

咨询热线
400-123-4657
400-123-4657
写在前面:多数关于多任务学习(Multi-task learning)的文章、综述或者paper都聚焦于网络结构的迭代与创新;然而,对于多任务学习Loss的优化也非常重要。本文基于多任务学习在2020年的一篇综述——《Multi-Task Learning for Dense Prediction Tasks: A Survey》中的部分内容,尽量用通俗易懂的方式来聊聊多任务学习优化的问题。
附一篇多任务学习相关文章链接《Rethink深度学习中的Attention机制》 , 这篇文章开篇讲述了MMoE。
以下是本文的主要框架:
全文大约6000字,阅读完大概需要15-20分钟。 PS:各位大佬不要只收藏阿,麻烦点个赞和喜欢~
大多数机器学习模型都是独立来进行学习的,即单任务学习(single-task learning)。也就是说,我们针对一个特定的任务,设计一个模型,然后进行迭代优化。对于稍复杂一点的任务,我们也习惯于通过进行拆解的方式,来对任务的每个部分进行建模。这样存在一个很明显的问题,在对每个子任务进行建模的时候,很容易忽略任务之间的关联、冲突和约束等关系,导致多个任务的整体效果无法更优。
多任务学习(multi-task learning),就是与单任务学习相对的一个概念。在多任务学习中,往往会将多个相关的任务放在一起来学习。例如在推荐系统中,排序模型同时预估候选的点击率和浏览时间。相对于单任务学习,多任务学习有以下优势:
目前,多数关于多任务学习(Multi-task learning)的文章、综述或者paper都聚焦于网络结构的迭代与创新,通常会谈到软参数共享 vs 硬参数共享;或者encoder-based MTL vs decoder-based MTL;然而,对于多任务学习Loss的优化也非常重要。本文希望聊聊这个问题。
本科修经济学双学位的时候,学到过关于“零和博弈”的问题。零和博弈是博弈论的一个概念,它指的是博弈的各个参与者,在严格竞争之下,一方的收益必然会带来另一方的损失。在零和博弈下,博弈参与者们的收益和损失相加总和永远为“零”。 换句话说,“损人利己”,再换句话说就是自己的幸福是建立在他人的痛苦之上。
零和博弈和多任务学习有一些共通之处。
我们以比较简单的硬参数共享的share bottom结构为例,来看看多任务学习:
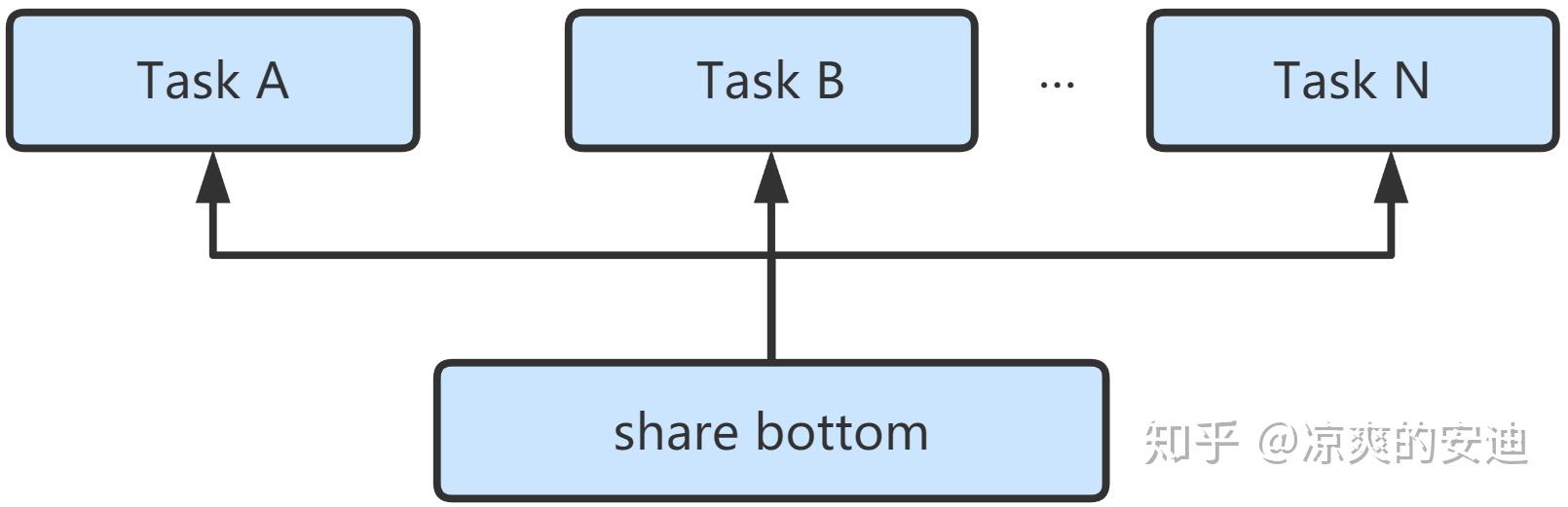
两个任务共享了input层和share bottom层,然后两个tower分别拟合两个任务的输出。对于多任务的loss,最简单的方式是直接将这两个任务的loss直接相加,得到整体的loss,那么loss函数为:
我们发现,整体的loss来源于不同任务loss之和。
这种loss计算方式的不合理之处是显而易见的,不同任务loss的量级很有可能不一样,loss直接相加的方式有可能会导致多任务的学习被某个任务所主导或学偏。当模型倾向于去拟合某个任务时,其他任务的效果往往可能受到负面影响,效果会相对变差(这是不是有一种零和博弈的感觉,当然也有跷跷板的感觉)。


我们对loss函数进行简单的调整,对每个任务地loss配置一个固定的权重参数,那么loss函数变为:
相对于loss直接相加的方式,这个loss函数对于每个任务的loss进行加权。这种方式允许我们手动调整每个任务的重要性程度;但是固定的w会一直伴随整个训练周期。
这种loss权重的设置方式可能也是存在问题的,不同任务学习的难易程度也是不同的;且,不同任务可能处于不同的学习阶段,比如任务A接近收敛,任务B仍然没训练好等。这种固定的权重在某个阶段可能会限制了任务的学习。
那么多任务学习中,不同任务的loss的更好的加权方式是什么呢?更好的加权方式应该是动态的,根据不同任务学习的阶段,学习的难易程度,甚至是学习的效果来进行调整。(关于w的参数t的含义,我们在下文中会进行提及)
接下来介绍的几个工作,主要是从不同任务loss的平衡的角度出发,动态调整不同任务loss的权重。
2-1. Gradient Normalization——梯度标准化
《Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks》,ICML 2018,Cites:177
【主要思想】:
【实现】:
下面的几个公式是Gradient Normalization的核心,目的是将Gradient Loss表示为一个关于loss权重的函数,我们来理解一下。
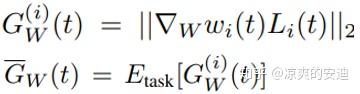
2. 其次,定义了一些变量来衡量任务的学习速度,其中:
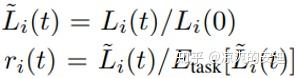
3. 最终,Gradient Loss(GL)为:
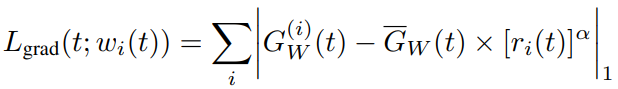
*
表示理想的梯度标准化的值;
直观来看:
计算完Gradient Loss后,通过以下函数对 进行更新(GL指Gradient Loss):
GradNorm的训练流程为:

【评价】:
优点:
Gradient Normalization既考虑了loss的量级,又考虑了不同任务的训练速度。
缺点:
2-2. Dynamic Weight Averaging ——动态加权平均
《End-to-End Multi-Task Learning with Attention》,CVPR 2019,Cites:107
【主要思想】:
DWA希望各个任务以相近的速度来进行学习。
【实现】:
下面的公式是DWA的核心算法:
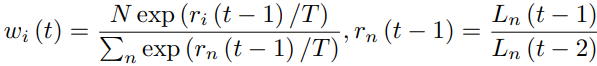
直观来看,loss缩小快的任务,则权重会变小;反之权重会变大。
【评价】:
优点:
只需要记录不同step的loss值,从而避免了为了获取不同任务的梯度,运算较快。
缺点:
没有考虑不同任务的loss的量级,需要额外的操作把各个任务的量级调整到差不多。
2-3. Dynamic Task Prioritization ——动态任务优先级
《Dynamic task prioritization for multitask learning》,ECCV 2018,Cites:53
【主要思想】:
DTP希望让更难学的任务具有更高的权重。
【实现】:
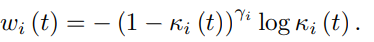
直观来看,KPI高的任务,学习起来比较简单,则权重会变小;反之,难学的任务权重会变大。
【评价】:
优点:
需要获取不同step的KPI值,从而避免了为了获取不同任务的梯度,运算较快
缺点:
DTP没有考虑不同任务的loss的量级,需要额外的操作把各个任务的量级调整到差不多;且需要经常计算KPI......
2-4. Uncertainty Weighting——不确定性加权
《Multi-task learning using uncertainty to weigh losses for scene geometry and semantics》
CVPR 2018, Cites:676
【主要思想】:
本文希望让“简单”的任务有更高的权重。
【背景】:
NIPS2017论文《What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?》中提到,当我们使用数据集,基于输入x和输出y训练模型的时候,面临两种不确定性(Uncertainties):认知不确定性(epistemic)和偶然不确定性(aleatoric)。
偶然不确定性可以分为两种情况:
其中,f是我们的函数,a和b是参数。“公司 + 工作类型”来预测工作时长时,本身就存在不确定性, 就是y中永远无法被x解释的部分,是一个随机变量,
就是由任务性质导致的任务依赖型不确定性;即使我们训练数据增加得再多,
仍然会存在。
而如果我们换了一个任务,我们希望通过”公司 + 工作类型“来预测所处行业,这个任务也存在误差,然而
可能天然就比
小很多。
【实现】:
回到《Multi-task learning using uncertainty …》,本文希望基于偶然不确定性(aleatoric)中的任务依赖型、同方差不确定性,来进行建模。即,对于某个样本而言,模型既预估一个标签 ,又预估任务依赖型同方差不确定性
。
接下来,简单描述下loss函数的推导过程:
对于单个回归任务而言,其条件概率可以写成如下的形式,其中 是不确定性:
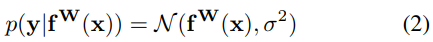
对于单个分类任务而言,模型输出一般会squash到一个softmax函数里
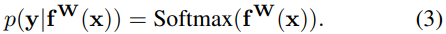
对于多任务学习而言,已知输入x, 到
的总的条件概率可以写成预估
到
每一个的条件概率的乘积:
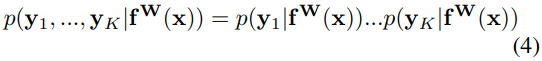
(2)式的对数似然函数正比于(5)式中右侧的部分(这一步是关键的一步,不过paper中没写推导,甚至其引用NIPS2017的paper中也没有推导。。感兴趣的小伙伴可以看看NIPS2017的paper的引用)。
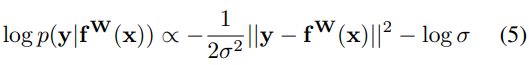
基于极大似然法对(5)式右侧的部分求极大,在神经网络里可以加一个负号求极小。
最终单个任务的loss函数为:
对于多任务而言:
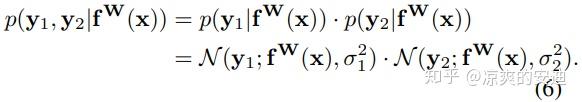
最终的loss函数为:
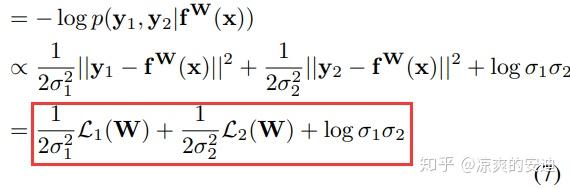
其中,和
是两个任务中,各自存在的不确定性。
直观来看,在一个预测任务里,如果网络可以完全overfiting到所有的样本点,那么 的结果应该是0,此时的神经网络变成了一个“记忆”网络,网络输出和输出之间完全变成了一种映射的关系,不确定性也自然就不存在了。
如果网络没有过于复杂,网络预测了数据的趋势,如上方举例的任务一样,但是误差用来衡量该任务中存在的不确定性。通过除以
,即
的方式,可以在一定程度上对该任务带来的不确定性进行消除。而
则类似于一个正则项的存在,防止
学得过大。
因此, 越大,任务的不确定性越大,则任务的权重越小,即噪声大且难学的任务权重会变小。
2-3和2-4的两个loss函数似乎存在在某种程度上是对立的。在2-3中,文章希望对于“难学”的任务给予更高的权重;而在2-4中,文章希望给“简单”的任务更高的权重。在综述中是这样写的:
We hypothesize that the two techniques do not necessarily conflict, but uncertainty weighting seems better suited when tasks have noisy labeled data, while DTP makes more sense when we have access to clean ground-truth annotations.
这两种方法不一定是完全冲突的,不确定性建模似乎可以适用于标签噪声更大的数据,而DTP可能在干净的标注数据里效果更好。(你是怎么看的呢?可以在评论区讨论一下)
3. Conclusion
本文中对于近年来几种多任务学习的loss优化方式进行了描述,主要总结如下:

重要的是,这些与优化方法与网络结构并不冲突,可以叠加产生更好的效果。快去你的多任务学习的模型里尝试一下吧 ^_^
转载前请私信!
最后的最后,求赞求收藏求关注~
参考文献

